Myślenie reactowe
These docs are old and won’t be updated. Go to react.dev for the new React docs.
The updated Thinking in React guide teaches modern React and includes live examples.
Naszym zdaniem React dostarcza pierwszorzędnych narzędzi do budowy dużych, szybkich aplikacji webowych. Znakomicie sprawdza się, na przykład, w naszych zastosowaniach na Facebooku i w Instagramie.
Jedną z wielu zalet Reacta jest to, jak praca z tą biblioteką uczy cię myśleć o aplikacjach, które tworzysz. Poniżej przybliżymy ci proces myślowy towarzyszący budowie przykładowego programu. Będzie to tabela z danymi o produktach z funkcją wyszukiwania, w całości zbudowana w Reakcie.
Zacznij od projektu
Załóżmy, że mamy już gotowy interfejs JSON API oraz projekt graficzny, który wygląda następująco:
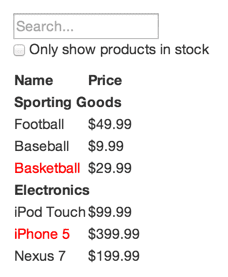
Nasz interfejs JSON API dostarcza następujących informacji:
[
{category: "Sporting Goods", price: "$49.99", stocked: true, name: "Football"},
{category: "Sporting Goods", price: "$9.99", stocked: true, name: "Baseball"},
{category: "Sporting Goods", price: "$29.99", stocked: false, name: "Basketball"},
{category: "Electronics", price: "$99.99", stocked: true, name: "iPod Touch"},
{category: "Electronics", price: "$399.99", stocked: false, name: "iPhone 5"},
{category: "Electronics", price: "$199.99", stocked: true, name: "Nexus 7"}
];Krok 1: Podziel interfejs użytkownika na zhierarchizowany układ komponentów
W pierwszej kolejności zakreśl na projekcie wszystkie komponenty (i podkomponenty) oraz nadaj im nazwy. Jeśli współpracujesz z zespołem designerów, możliwe, że oni zrobili to już za ciebie. Koniecznie skontaktuj się z nimi. Nazwy komponentów reactowych często biorą się z nazw nadanych warstwom w Photoshopie.
Skąd wiadomo, co powinno być komponentem? Zastosuj te same metody, których używamy tworząc nowe funkcje lub obiekty. Jedną z takich metod jest Zasada jednej odpowiedzialności, zgodnie z którą każdy komponent powinien być odpowiedzialny za tylko jedną rzecz. Jeśli komponent nie spełnia tej zasady i odpowiada za więcej rzeczy, należy go rozbić na kilka mniejszych komponentów.
Model danych wyświetlanych użytkownikowi często odpowiada modelowi zawartemu w plikach JSON. Dlatego jeśli właściwie skonstruujesz swój model, twój interfejs użytkownika (a co za tym idzie także twój układ komponentów) zostanie właściwie zmapowany. Wiąże się to z faktem, że interfejsy użytkownika i modele danych zwykle stosują się do tych samych zasad architektury informacji. Wszystko to zaś oznacza, że zadanie podziału interfejsu użytkownika na komponenty jest zwykle zadaniem dziecinnie prostym. Po prostu podziel go tak, aby jednemu elementowi twojego modelu danych odpowiadał jeden komponent.
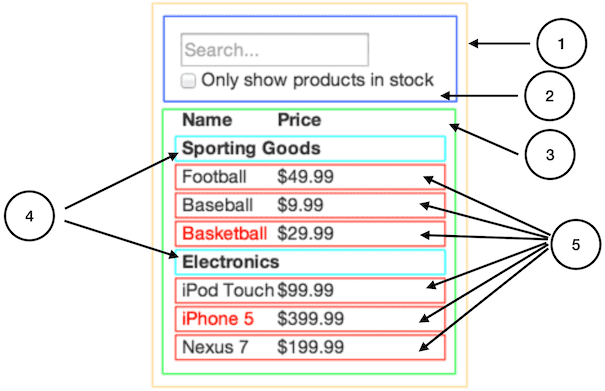
Zwróć uwagę, że nasza prosta aplikacja składa się z pięciu komponentów. Dane, za które odpowiedzialne są poszczególne komponenty, zaznaczyliśmy kursywą. Numery umieszczone na obrazku odpowiadają numerom poniżej.
FilterableProductTable(pol. tabela produktów z wyszukiwaniem; pomarańczowy): mieszczą się w nim wszystkie pozostałe komponentySearchBar(pol. pasek wyszukiwania; niebieski): odbiera wpisane przez użytkownika słowo lub frazę (szukana fraza)ProductTable(pol. tabela produktów; zielony): wyświetla i filtruje kolekcję danych na podstawie szukanej frazyProductCategoryRow(pol. wiersz rodzaju produktu; turkusowy): wyświetla nagłówek dla każdego rodzaju produktówProductRow(pol. wiersz produktu; czerwony): wyświetla wiersz dla każdego produktu
Zauważ, że nagłówek naszej ProductTable (zawierający nazwy kolumn “Name” i “Price”) nie jest osobnym komponentem, chociaż mógłby nim być. W tym przypadku jest to bardziej kwestia naszych indywidualnych preferencji niż zasada ogólna dla tego typu elementów. W naszej przykładowej aplikacji uznaliśmy ten nagłówek za integralną część komponentu ProductTable, ponieważ wyświetlany jest razem z danymi zebranymi, a wyświetlanie danych zebranych jest odpowiedzialnością ProductTable. Jeśli jednak element ten miałby się w naszej aplikacji rozrosnąć (tzn. gdybyśmy mieli dodać do niego funkcję sortowania), jak najbardziej wskazane byłoby zrobienie z niego osobnego komponentu ProductTableHeader.
Teraz, kiedy już określiliśmy, które z elementów projektu graficznego mają być komponentami, ułożymy je w odpowiedniej hierarchii. Nie jest to zbyt trudne. Komponenty występujące wewnątrz innych komponentów przedstawimy w naszej hierarchii jako komponenty potomne.
-
FilterableProductTableSearchBar-
ProductTableProductCategoryRowProductRow
Krok 2: Zbuduj wersję statyczną w Reakcie
Skoro wiemy już, jak wygląda hierarchia naszych komponentów, możemy zacząć ją wdrażać. Budowę aplikacji najłatwiej jest zacząć od wersji statycznej, tzn. takiej, która wyrenderuje interfejs użytkownika na podstawie naszego modelu danych, ale nie będzie zawierała żadnych elementów interaktywnych. Dobrze jest rozdzielić te procesy, ponieważ budowa wersji statycznej wymaga więcej pisania niż myślenia, podczas gdy dodawanie interaktywności wymaga więcej myślenia niż pisania. Za chwilę zobaczysz dlaczego.
Aby zbudować statyczną wersję aplikacji, która wyrenderuje nasz model danych, musimy stworzyć komponenty, które będą korzystać z innych komponentów i przekazywać dane za pomocą atrybutów (ang. props). Atrybuty umożliwiają przekazywanie danych z komponentu nadrzędnego do komponentu potomnego. Jeśli wiesz już, czym jest stan w Reakcie, powstrzymaj się przed zastosowaniem go tutaj. Nie należy używać stanu do budowy statycznych wersji aplikacji. Stan wiąże się wyłącznie z interaktywnością, tzn. danymi zmieniającymi się w czasie.
Tworzenie naszej aplikacji możemy rozpocząć albo od komponentów znajdujących się wysoko w hierarchii (w naszym przypadku od FilterableProductTable), albo od tych znajdujących się na samym dole (ProductRow). Zazwyczaj, budując proste aplikacje, zaczyna się od góry, natomiast w przypadku projektów większych łatwiej jest zacząć pracę od dołu hierarchii, jednocześnie pisząc testy dla poszczególnych funkcjonalności.
Kończąc ten etap pracy nad aplikacją będziemy mieli dostępną bibliotekę komponentów wielokrotnego użytku, które renderują nasz model danych. Komponenty te będą miały tylko jedną metodę render() (pol. renderuj) ponieważ jest to statyczna wersja aplikacji. Komponent na szczycie hierarchii komponentów (FilterableProductTable) wykorzysta nasz model danych jako atrybut. Każda zmiana w naszym modelu danych w połączeniu z ponownym wywołaniem root.render() spowoduje aktualizację interfejsu użytkownika. Cały proces aktualizacji interfejsu jest bardzo prosty, a ponieważ wszelkie zmiany są od razu widoczne, łatwo można się zorientować, które fragmenty kodu wymagają poprawy. Jednokierunkowy transfer danych w Reakcie (nazywany również wiązaniem jednokierunkowym, ang. one-way binding) zapewnia modularność kodu i szybkie działanie aplikacji.
Jeśli potrzebujesz pomocy na tym etapie budowy aplikacji, zajrzyj do Dokumentacji Reacta.
Krótki przerywnik: atrybuty a stan
W Reakcie wyróżniamy dwa modele danych: atrybuty i stan. Bardzo ważne jest zrozumienie, czym dokładnie modele te się różnią. Dla przypomnienia rzuć okiem na oficjalną dokumentację Reacta. Możesz także zajrzeć do odpowiedzi FAQ: Jaka jest różnica między stanem a atrybutami?
Krok 3: Określ minimalne (ale kompletne) odwzorowanie stanu interfejsu użytkownika
Aby interfejs użytkownika mógł zawierać elementy interaktywne, musimy mieć możliwość dokonywania zmian w modelu danych, na którym opiera się nasza aplikacja. W Reakcie jest to bardzo łatwe dzięki stanowi.
Poprawna budowa aplikacji wymaga w pierwszej kolejności określenia minimalnego zmiennego zestawu danych dla stanu aplikacji. Kluczowa jest tutaj reguła DRY: Don’t Repeat Yourself (pol. Nie powtarzaj się). Zadecyduj, jak ma wyglądać najprostsze możliwe odwzorowanie stanu aplikacji, a wszystko inne generuj dopiero wtedy, gdy pojawi się taka potrzeba. Przykładowo, jeśli tworzysz aplikację, która ma zarządzać “Listą rzeczy do zrobienia”, zachowaj “pod ręką” jedynie tablicę z rzeczami do zrobienia; nie ma potrzeby tworzenia osobnej zmiennej stanu przechowującej liczbę tych rzeczy. Kiedy zachodzi potrzeba wyrenderowania liczby rzeczy do zrobienia, po prostu pobierz długość tablicy.
Przyjrzyjmy się wszystkim rodzajom informacji w naszej przykładowej aplikacji. Mamy tutaj:
- Początkową listę produktów
- Frazę wyszukiwania podaną przez użytkownika
- Wartość odznaczonego pola
- Listę produktów spełniających kryteria wyszukiwania
Aby zdecydować, która z powyższych informacji zalicza się do stanu, w przypadku każdej z nich musimy zadać sobie trzy pytania:
- Czy informacja ta jest przekazywana za pomocą atrybutu? Jeśli tak, to prawdopodobnie nie wchodzi w skład stanu.
- Czy informacja ta pozostanie niezmienna na przestrzeni czasu? Jeśli tak, to prawdopodobnie nie wchodzi w skład stanu.
- Czy informację tę można wygenerować na podstawie innego stanu lub atrybutu w danym komponencie. Jeśli tak, to nie należy zaliczyć jej do stanu.
Początkowa lista produktów jest przekazywana jako atrybut, zatem nie jest stanem. Wyszukiwana fraza i wartość odznaczonego pola wydają się wchodzić w skład stanu, ponieważ mogą ulegać zmianom i nie da się ich w żaden sposób wygenerować. Jeśli chodzi o listę produktów spełniających kryteria wyszukiwania, to nie jest ona stanem, ponieważ może być wygenerowana na podstawie wyszukiwanej frazy i wartości odznaczonego pola.
Zatem ostatecznie nasz stan przestawia się następująco:
- Fraza wyszukiwania podana przez użytkownika
- Wartość zaznaczonego pola
Krok 4: Określ, gdzie powinien mieścić się stan
Mamy zatem określony minimalny zestaw danych stanu aplikacji. Teraz musimy określić, który z naszych komponentów ulega zmianom, czyli do którego komponentu należy stan.
Pamiętaj: Dane w Reakcie płyną tylko w jedną stronę - z góry w dół hierarchii komponentów. Przynależność stanu do danego komponentu nie jest sprawą oczywistą i często przysparza problemów na początku pracy z Reactem. Aby to dobrze zrozumieć, postępuj zgodnie z następującymi wskazówkami:
Dla każdego elementu stanu w twojej aplikacji:
- Określ każdy komponent, który coś renderuje na podstawie danego elementu stanu.
- Znajdź wspólnego właściciela stanu (tzn. komponent znajdujący się w hierarchii wyżej od wszystkich pozostałych komponentów wykorzystujących dany element stanu).
- Stan powinien należeć do wspólnego właściciela lub po prostu do innego komponentu znajdującego się wyżej w hierarchii komponentów.
- Jeśli trudno ci określić właściwe miejsce umieszczenia stanu, stwórz nowy komponent, którego jedynym celem będzie przechowywanie stanu. Ulokuj go w hierarchii komponentów gdzieś powyżej komponentu będącego wspólnym właścicielem.
Zastosujmy tę strategię w pracy nad naszą aplikacją:
ProductTablewymaga stanu, aby filtrować listę produktów.SearchBarwymaga stanu, aby wyświetlać wyszukiwaną frazę i wartość zaznaczonego pola- Wspólnym właścicielem jest
FilterableProductTable. - Sensownym rozwiązaniem jest umieszczenie wyszukiwanej frazy i wartości zaznaczonego pola w
FilterableProductTable
No dobra. Zatem ustaliliśmy, że stan umieścimy w FilterableProductTable. Teraz do konstruktora tego komponentu dodajemy właściwość instancji this.state = {filterText: '', inStockOnly: false}, aby ustalić początkowy stan naszej aplikacji. Następnie za pomocą atrybutów podajemy filterText oraz inStockOnly do komponentów ProductTable i SearchBar. Na końcu użyjemy tych atrybutów, aby przefiltrować wiersze ProductTable i ustawić wartość pola formularza w SearchBar.
Teraz widać już, jak będzie działała nasza aplikacja: ustawiamy filterText na ciąg znaków "ball" i odświeżamy aplikację. Nasza tabela danych poprawnie wyświetla nowe informacje.
Krok 5: Dodaj przepływ danych w drugą stronę
Jak dotąd zbudowaliśmy aplikację, która poprawnie wyświetla informacje dostarczone przez atrybuty i stan, spływające w dół hierarchii komponentów. Nadszedł czas, aby umożliwić przepływ danych w przeciwnym kierunku: komponenty formularza głęboko wewnątrz hierarchii muszą mieć możliwość aktualizowania stanu FilterableProductTable.
W Reakcie ten przepływ danych jest jawny. Pozwala to łatwo zobaczyć działanie aplikacji, ale zarazem wymaga trochę więcej kodu niż tradycyjne wiązanie dwukierunkowe (ang. two-way binding).
Jeśli spróbujesz wpisać coś do paska wyszukiwania albo zaznaczyć pole wyboru w poprzedniej wersji naszego przykładu (krok 4), React zignoruje dostarczone przez ciebie dane. Jest to działanie zamierzone, które wynika stąd, że wartość atrybutu value dla elementu input ustawiliśmy jako zawsze równą stanowi state podanemu z komponentu FilterableProductTable.
Zastanówmy się nad tym, co chcemy żeby się działo. Chcemy, aby stan aktualizował się i odzwierciedlał treść formularza za każdym razem, kiedy użytkownik dokona w formularzu zmian. Ponieważ komponenty powinny aktualizować jedynie własny stan, FilterableProductTable poda funkcję zwrotną (ang. callback) do paska wyszukiwania SearchBar, która to funkcja zostanie wywołana przy każdej aktualizacji stanu. Jeśli chcemy być o tym za każdym razem poinformowani, możemy dodać zdarzenie onChange do elementów naszego formularza. Funkcje zwrotne podane przez FilterableProductTable wywołają setState() i stan aplikacji zostanie zaktualizowany.
Może wydawać się, że powyższy proces jest skomplikowany, ale w rzeczywistości to tylko kilka linijek kodu, a przepływ danych w całej aplikacji jest naprawdę jawny i łatwy do prześledzenia.
To byłoby na tyle
Mamy nadzieję, że niniejszy przewodnik przybliżył ci myślenie reactowe, tzn. główne zasady, którymi kierujemy się tworząc komponenty i aplikacje z użyciem React.js. Być może stosowanie tej biblioteki wymaga pisania większej ilości kodu niż inne znane ci biblioteki i frameworki, pamiętaj jednak, że kod czyta się znacznie częściej niż tworzy, a czytanie kodu napisanego w Reakcie nie przysparza problemów ze względu na jego modularność i przejrzystość. Zalety tej przejrzystości i modularności na pewno docenisz tworząc duże biblioteki komponentów. Natomiast wielokrotne stosowanie gotowych kawałków kodu zaoszczędzi ci wiele pracy. :)